广度优先搜索(breadth-first search)是一种解决最短路径问题的算法,通常需要:
- 使用图来建立问题模型。
- 使用广度优先搜索解决问题。
那么,什么是图呢?
图模拟一组连接,比如说,假设你与朋友玩牌,并要模拟谁欠谁钱,可以下面这样指出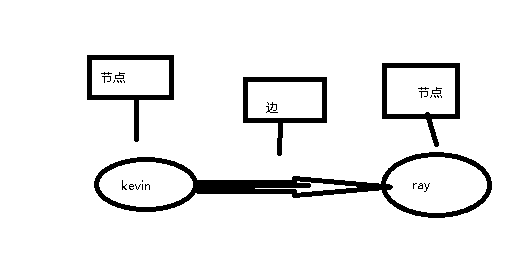
图由节点(node)和边(edge)组成。
广度优先搜索可以帮助我们解决以下两类问题:
1.从节点A出发,能到达节点B吗?
2.从节点A出发,前往节点B的哪条路最短。
我们先来解决第一个问题, 假设有这样一个欠钱的关系图,
过年了,债主纷纷要帐,都知道欠钱的是大爷,现在kevin这个大爷想, 钱我可以还,但还钱前,我想找美女陪我吃顿饭,这下,债主们(alex, bob)纷纷傻了,我俩都是大老爷们啊,怎么办? 去请一个美女过来,还得花钱呐,干脆,我也找我的债主提要求去,于是alex和bob又对他们的债主提出来相同的问题。
Alex没有债主,于是他只好希望Bob能找到,Bob找到了Hult和steven, steven也没有债主,他就等Hult,Hult正好欠Buauty这个美女的钱,于是这样一层一层,终于找到了Beauity,Kevin大爷和Beauty吃端饭,把钱还了,皆大欢喜。
我们来代码实现它,首先把问题转化成图:
图由多个节点组成。
每个节点都与邻近节点相连,如果表示类似于“kevin→Bob”这样的关系呢?好在你知道的一种结构让你能够表示这种关系,它就是散列表!
散列表让你能将键映射到值, 这种映射关系, python里的实现是字典。
|
|
查找的方式是:
0.创建一个队列,队列里是待查找的元素,再创一个列表,列表里是已经检查过的元素。
1.把队列元素依次弹出,看它在不在列表,在表示已经查过了,不需要做任何操作,不在,把它加入列表,然后看看弹出的元素有没有符合条件的。。
2.如果有直接退出
3.如果没有,看弹出的元素,还有没有债主,有就把它的债主加入到这个队列里。、
4.重复第1到3步,直到找到美女或者队列为空。
代码如下:
|
|
第一个问题从A点到B点有没有解的问题,我们已经解决了,但我们的程序没有把最短路径拿出来,下面来看,如何找最短路径。
根据图的关系,假设我们已经找到了最终的元素Beauty,那么,就意味着我们找到了最短路径,为什么这么说呢,因为我们是从一层一层找下来的,从图来看,有3层,第一层是kevin,第二层是alex, bob, 第3层是steven, hult,第4层是beauty。 那么初始节点出发(第一层),我们首先遍历了第2层所有的子节点,
alex和bob,都没有我们要找的元素,然后我们走向第3层,hult,steven,也没有我们找的元素,但是第3层的hult指向了第4层的一个元素,也就是我们的目标。既然找到了目标,我们反过来查目标的上一个元素是谁,就可以一层一层回溯到起始节点。
下面来实现下:
代码不是很好看,优化一下:
好了,现在广度优先搜索大家也会了,广度优先搜索还有个非常经典的练习题目就是迷宫问题,大家可以尝试解解看,原理是一样的。有问题可以给我留言。


